
AWS Container (2) - ECS
2024년 8월 20일 작성
ECS
ECS 서비스 오토스케일링
- ECS 태스크를 오토스케일링 한다.
- ECS 오토스케일링은
AWS Application Auto Scaling을 사용한다. 방법은 세 가지가 있는데,- ECS SErvice Average CPU Utilization
- ECS Service Average Memory Utilization - Scale on RAM
- ALB Request Count Per Target - metric coming from ALB
- Target Tracking: 특정 Cloudwatch metric 을 target value로 설정, 그에 기반해서 스케일링을 한다.
- Step Scaling: 특정 CloudWatch 알람을 기반으로 스케일링한다.
- Scheduled Scaling: 주어진 date/time 에 스케일링한다. (predictable changes)
주의해야하는 것은, ECS 서비스 오토스케일링은 task level 에서의 스케일링이라, ECS 오토스케일링과는 다른 개념이다. ECS 오토스케일링은 EC2 인스턴스 레벨의 것이다. Fargate 사용시에는 우리가 관리하는 EC2가 사라지므로, (서버리스) ECS 오토스케일링을 설정하는 것이 권장된다.
EC2 Launch Type - Auto scaling EC2 instances
EC2 Launch Type에서 오토스케일링을 사용할 수 있는 방법엔 크게 두 가지가 있다.
Auto Scaling Group 스케일링
- CPU 사용량을 기반으로 ASG를 스케일링 할 수 있다.
- EC2 인스턴스가 추가된다.
ECS Cluster Capacity Provider
전 핸즈온에서 봤던 기능! ASG 보다 좀 더 똑똑한 방식이다. "태스크를 새로 만들 리소스가 부족하면", 자동으로 ASG를 스케일링 해주는 기능이다.
- ECS 태스크를 위한 인프라를 자동으로 프로비저닝하고 스케일링할 수 있다.
- Capacity Provider는 ASG와 쌍으로 사용할 수 있다.
- 태스크 추가 시 만약 missing capacity가 있다면 EC2 인스턴스를 추가한다.
- 태스크 중심으로 EC2 인스턴스를 관리하기 때문에, 인스턴스 자원을 더 효율적으로 사용할 수 있다.
- e.g. 태스크가 새로운 인스턴스를 생성하지 않고 비용을 절감
ASG는 단순히 EC2 인스턴스의 상태를 기준으로 동작해. ECS에서 태스크가 부족해도 이를 인식하지 못할 수 있다. 따라서 만약 ECS에서 EC2 런치 타입을 사용한다면, 대개 후자를 선택하는 것이 더 좋은 방법이다.
하지만 Capacity Provider가 더 진보된 방식이라고 무조건 저렴하거나 좋은 것은 아니니 직접 고민해봐야한다.
두 가지 방식을 비교한 시나리오 (GPT 답변)
물론이야! 예시를 통해 두 가지 방식이 어떻게 동작하는지 설명할게.
시나리오 1: Auto Scaling Group (ASG)만 사용
-
환경 설정: 웹 애플리케이션이 EC2 인스턴스에서 호스팅되고 있고, ASG를 사용해 CPU 사용량이 70% 이상일 때 인스턴스를 추가하고, 30% 이하일 때 인스턴스를 줄이도록 설정했다고 가정해.
-
상황 1 - 트래픽 증가: 사용자가 많아져 CPU 사용량이 80%에 도달했어. ASG는 이 값을 감지하고 새로운 EC2 인스턴스를 1대 더 추가해. 이제 인스턴스가 2대가 되었고, 트래픽이 분산되면서 CPU 사용량이 다시 50%로 떨어졌어.
-
상황 2 - 트래픽 감소: 트래픽이 줄어들면서 CPU 사용량이 20%로 떨어졌어. ASG는 이 값을 감지하고 EC2 인스턴스를 1대 줄였어. 다시 인스턴스는 1대로 돌아갔어.
-
문제점: 이 시나리오에서는 CPU 사용량만 기준이 되었어. 만약 ECS에서 여러 태스크를 실행 중이었는데, CPU 사용량이 낮아 ASG가 인스턴스를 줄인다면 태스크가 필요한 만큼의 리소스를 얻지 못하게 될 수 있어. 반대로, 태스크가 줄어들었더라도 CPU 사용량이 높다면 불필요한 인스턴스를 추가하게 되어 비용이 증가할 수 있어.
시나리오 2: ECS Cluster Capacity Provider 사용
-
환경 설정: 동일한 웹 애플리케이션이 ECS 클러스터에서 호스팅되고 있고, Capacity Provider를 사용해 태스크 수요에 따라 인스턴스를 조절하도록 설정했다고 가정해.
-
상황 1 - 태스크 수요 증가: 새로운 기능이 추가되어 더 많은 태스크가 필요해졌어. 하지만 현재 실행 중인 EC2 인스턴스로는 이 모든 태스크를 실행하기에 자원이 부족해. Capacity Provider는 이를 감지하고 ASG를 통해 EC2 인스턴스를 1대 더 추가해. 이제 모든 태스크가 정상적으로 실행될 수 있어.
-
상황 2 - 태스크 수요 감소: 한편, 밤이 되어 사용자 트래픽이 줄어들면서 실행 중인 태스크가 줄어들어도 충분한 자원이 남아. 이때 Capacity Provider는 사용되지 않는 EC2 인스턴스를 자동으로 제거해. 결과적으로 남아 있는 인스턴스만으로도 태스크를 처리할 수 있게 되었고, 비용이 절감돼.
-
장점: 이 시나리오에서는 ECS 태스크의 상태에 따라 인스턴스 수가 조절되었기 때문에 불필요한 인스턴스가 운영되지 않았어. 결과적으로 태스크 실행에 필요한 최소한의 자원만 사용하게 되어 비용 절감 효과가 있었어.
핵심 차이
-
ASG만 사용하는 경우: CPU 사용량과 같은 메트릭을 기준으로 인스턴스 수를 조절해. 태스크 수요와는 상관없이 CPU 사용량이 증가하면 추가 인스턴스를 생성할 수 있고, 반대로 사용량이 감소하면 태스크가 필요한 리소스가 부족해질 수 있어.
-
ECS Cluster Capacity Provider를 사용하는 경우: 태스크 수요를 기준으로 인스턴스를 조절해. 태스크가 실행될 수 있는 최소한의 인스턴스만 유지하도록 관리해 불필요한 비용을 줄일 수 있어.
이 예시에서 볼 수 있듯이, ECS 환경에서는 Capacity Provider를 사용함으로써 태스크 중심의 자원 관리를 통해 더 효율적이고 비용 절감이 가능한 운영이 가능해져.
ECS Scaling - Service CPU Usage Example
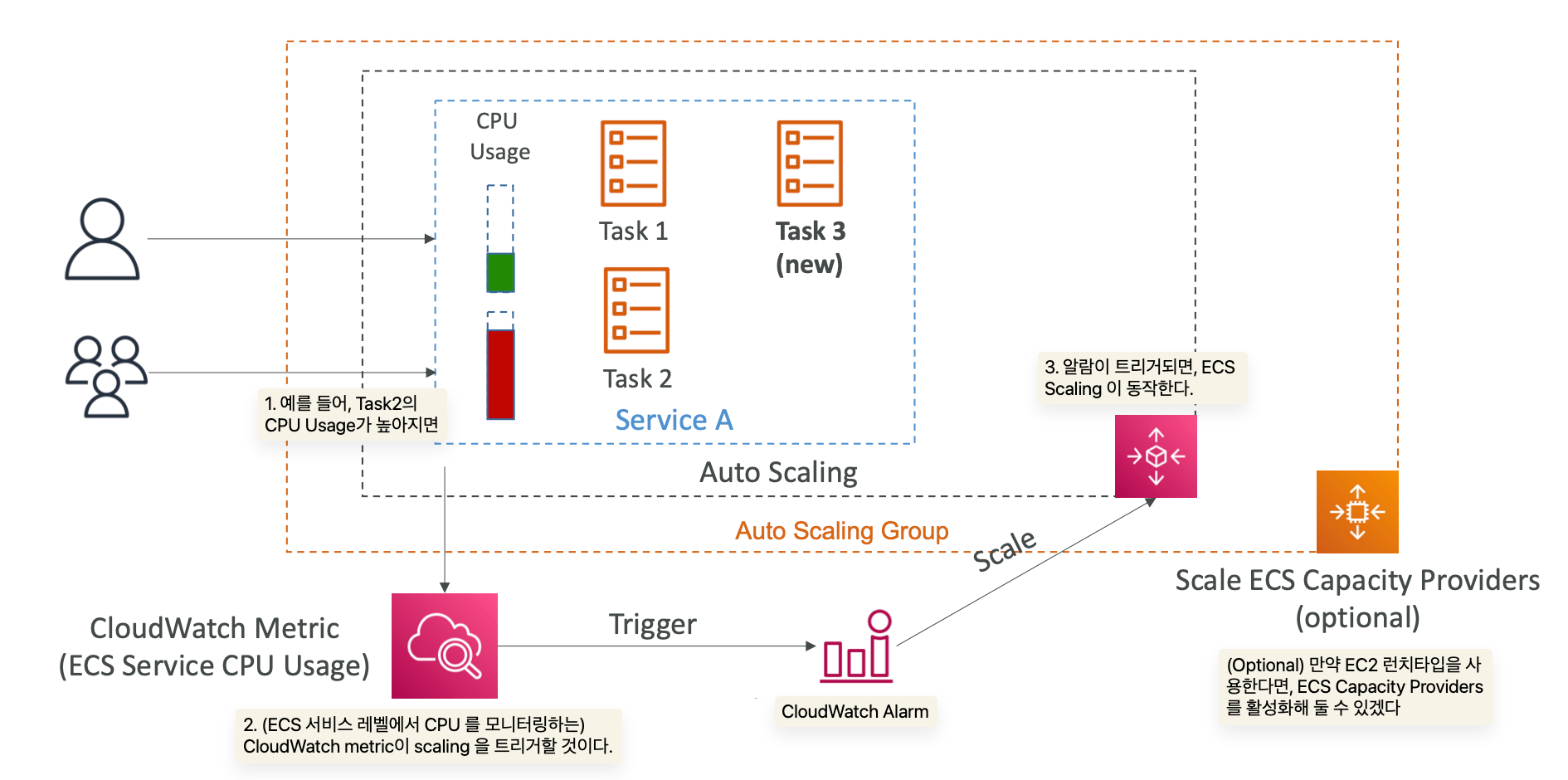
Amazon ECS - Solutions Architect
지금부터는 ECS를 이용한 몇가지 솔루션 예시들을 설명할 것이다.
-
ECS tasks invoked by Event Bridge : 다음 예시와 같이 이벤트 브릿지 rule 로 ECS 태스크를 실행할 수 있다.
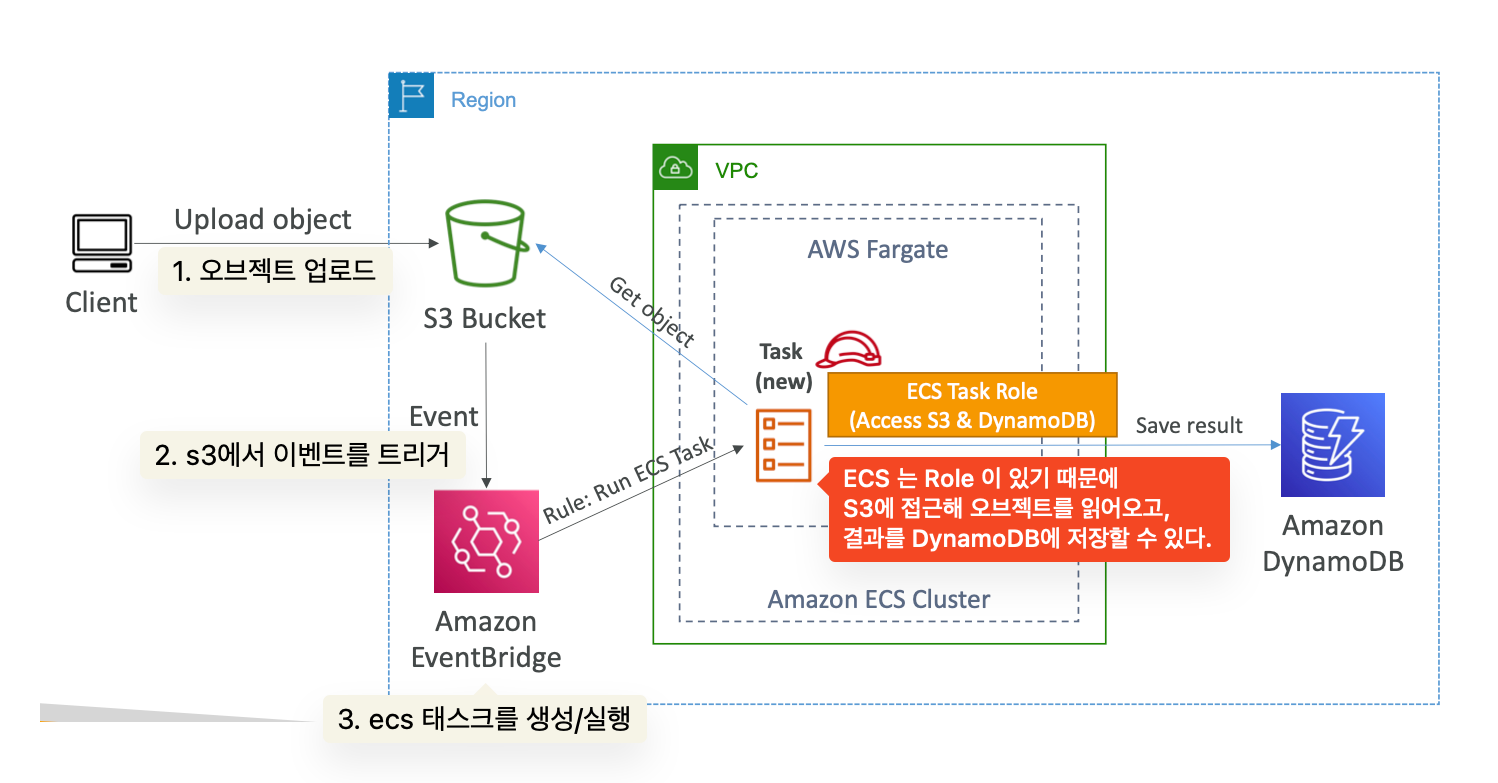
사용자가 s3 에 오브젝트를 올리면, 해당 오브젝트를 읽어와 프로세싱하고 결과를 dynamoDB에 저장하는데, 이는 ECS Task가 권한을 붙여줘야 가능한 것이다.
-
ECS tasks invoked by Event Bridge Schedule : 이벤트 브릿지의 스케줄 기능을 이용한 또다른 솔루션이다. 한 시간마다 ECS 태스크를 실행하게 만드는 방식을 만들어볼 수 있을 것이다.
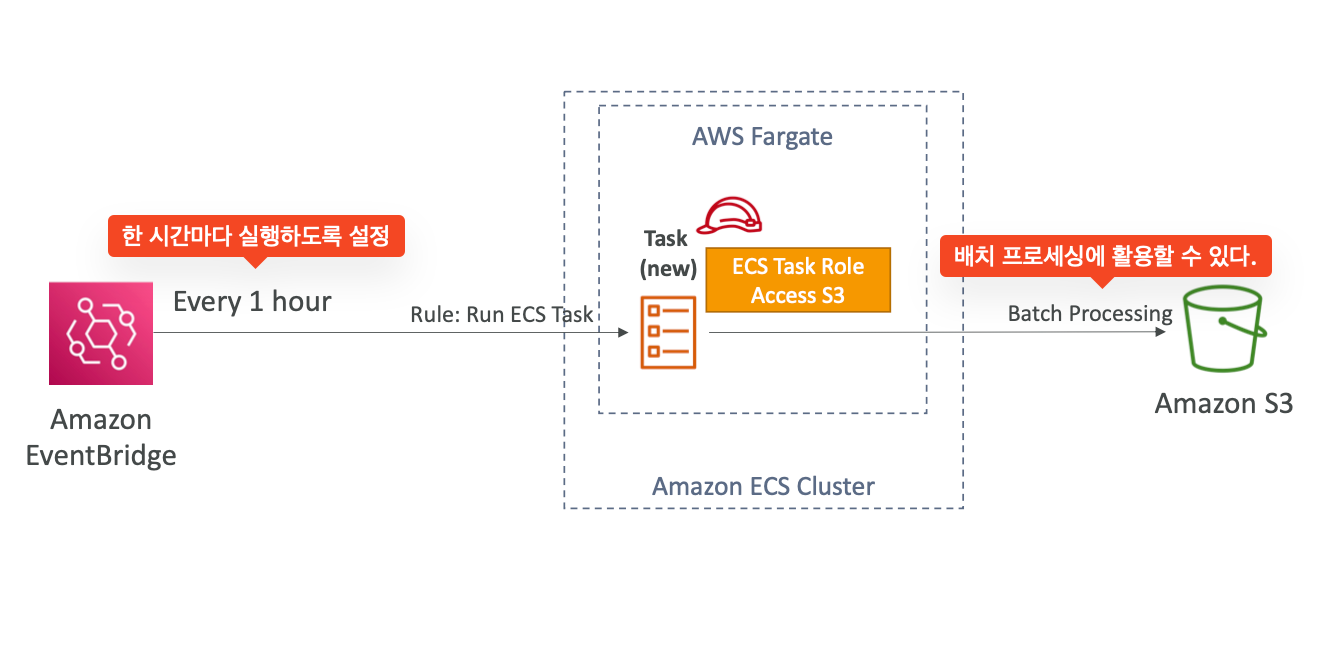
-
ECS - SQS Queue : 서비스에서 SQS 메시지를 폴링하도록 할 수 있다. 메시지가 많아지면, ECS Service Auto Scaling 이 태스크를 새로 만들어 병목을 방지할 수 있다.
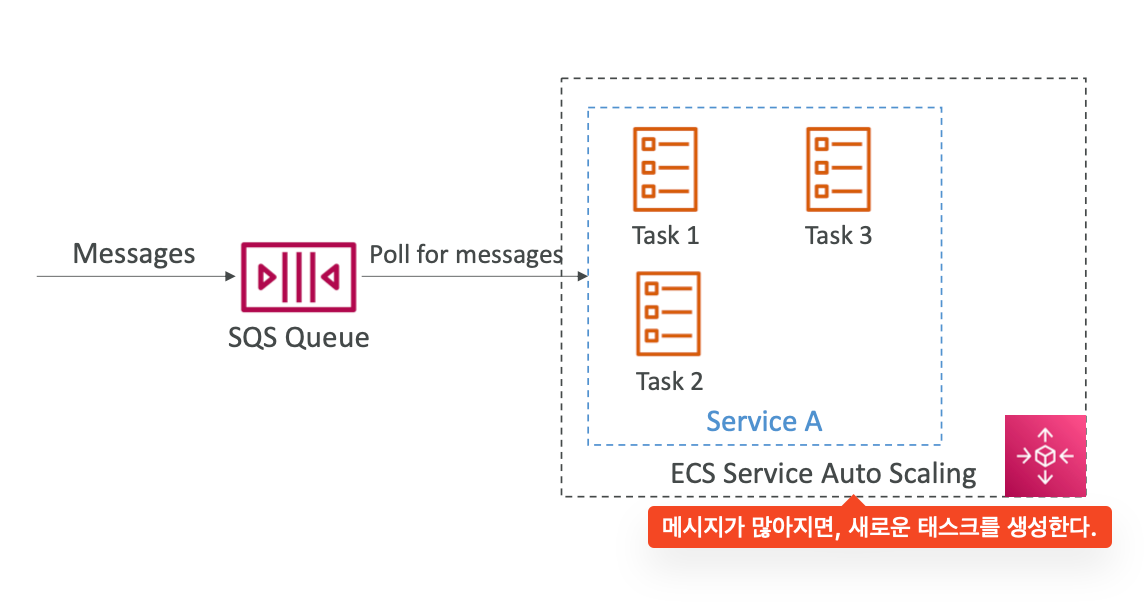
-
ECS - Intercept stopped tasks using EventBridge : ECS 클러스터에서 태스크가 종료되었다는 이벤트를 트리거 할 수 있다.
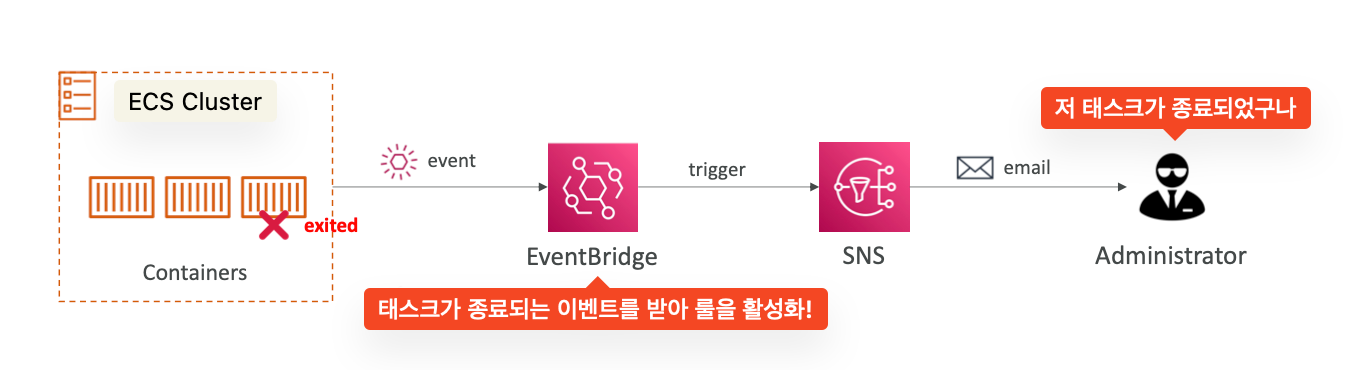
이벤트 브릿지는 다음과 같이 설정할 수 있겠다.
{ "source": [ "aws.ecs" ], "detail-type": [ "ECS Task State Change" ], "detail": { "lastStatus": [ "STOPPED" ], "stoppedReason": [ "Essential container in task exited" ] } }
ECS Clean Up
ECS 클러스터는 cloudformation을 통해서 만들어지기 때문에 스택에서 모든 리소스를 확인하고 한번에 삭제하는 것이 간편하다. 그렇지 않으면 남아있는 리소스가 있을 수 있다. (실제로 나도 다 삭제한 줄 알았는데 로드밸런서가 남아있었다.)
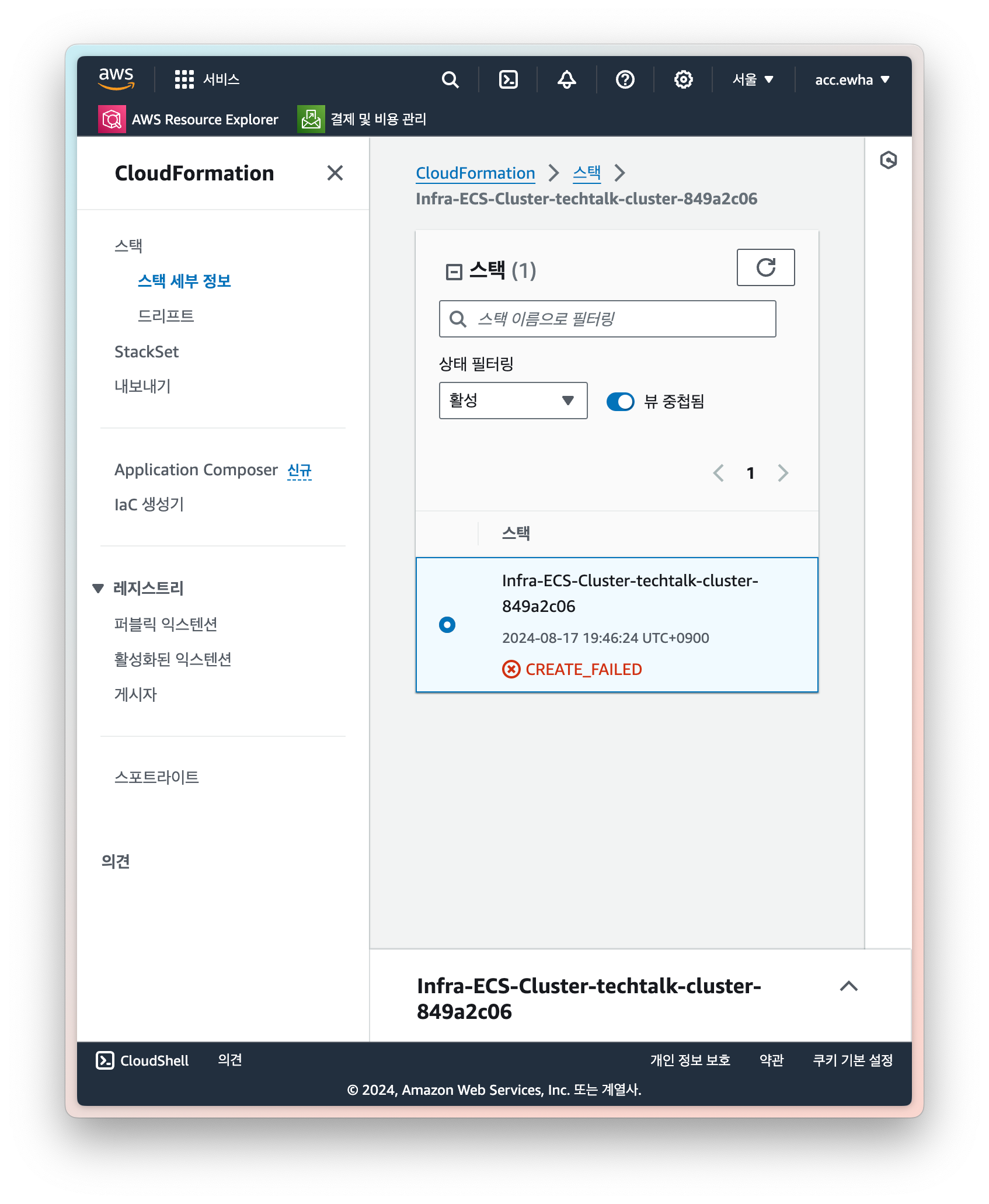
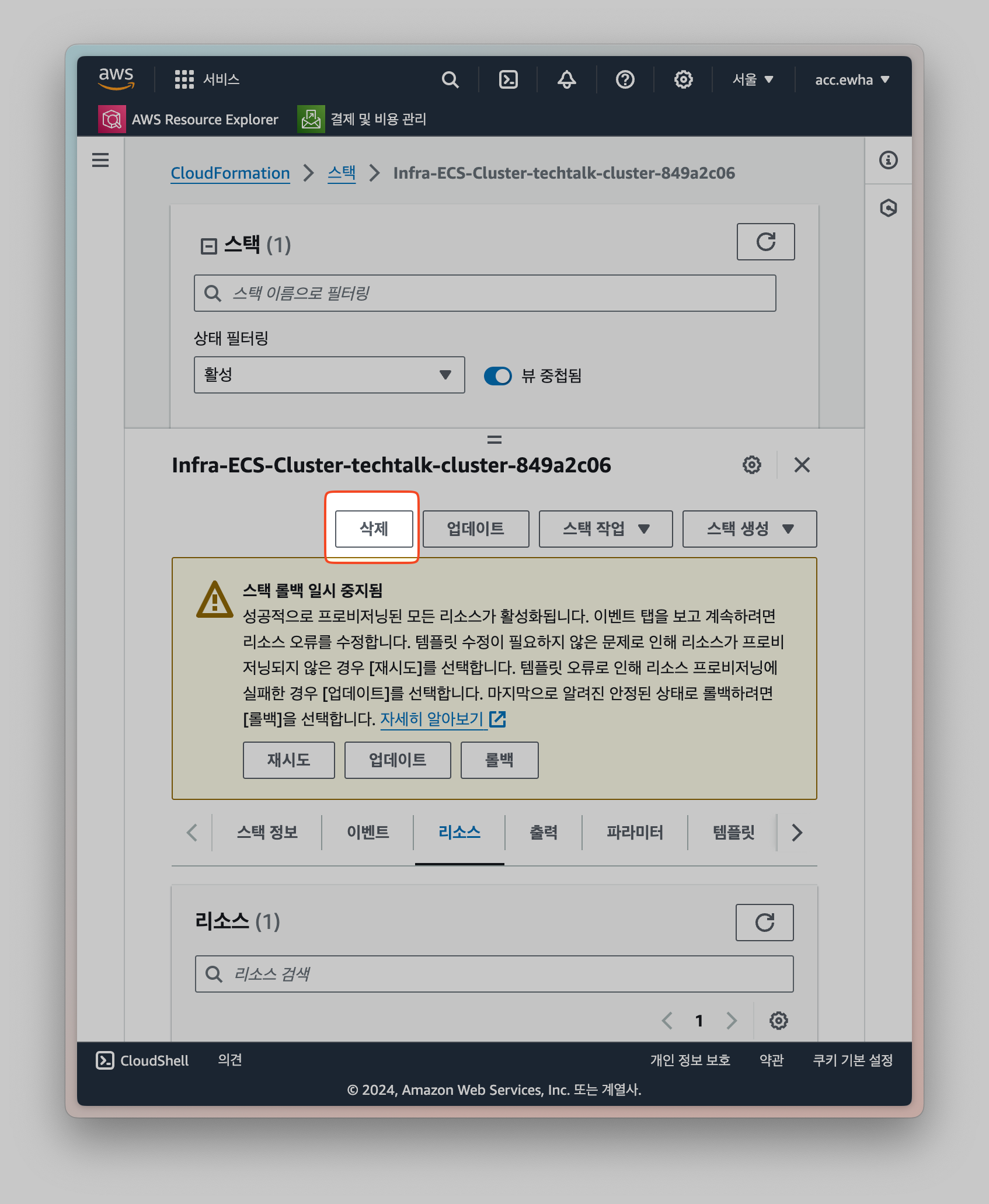
-
task definition은 과금이 되지 않는다. (정의일 뿐이다.) 그래도 삭제하고 싶은 경우 들어가서 등록취소해주면 된다.
삭제까지 완료 :D
ECS 에 대해 알아봤으니, 짧게 ECR 에 대해서도 짚고 넘어가려한다.
Amazon ECR
-
ECR 은 Elastic Container Registry 의 약자다.
-
AWS에서 도커 이미지를 저장하고 관리할 수 있다.
-
Private/Public 리포지토리가 있다.
-
ECS 와 함께 사용할 수 있고, 이미지는 s3에 저장되도록 구현되어있다.
-
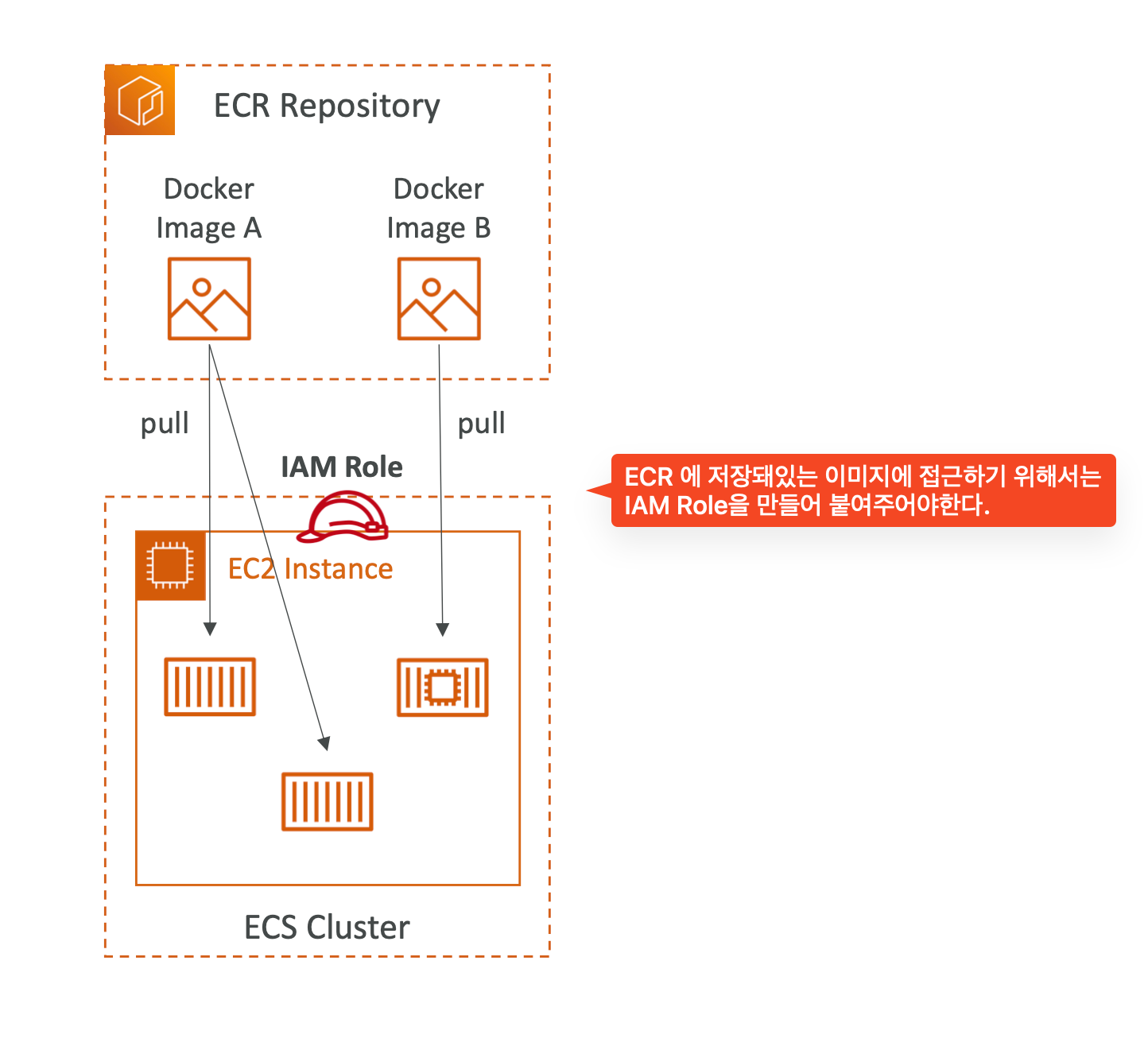
만약 ECS 클러스터에서 ECR 에 대한 접근이 필요한 경우, IAM Role 을 만들어 적용해주어야한다.
-
ECS 는 이미지 취약점 스캔, 버져닝, 이미지 태그, 이미지 라이프사이클 관리 등 이미지 관리 기능을 제공하기도 한다.
지금까지 ECS 내용과 핸즈온을 해보고 ECR 내용도 훑어봤다. 다음 글에서는 EKS 내용을 보는 것으로 :)