
실전 카프카 개발부터 운영까지 - 1. 카프카 개요
2025년 6월 15일 작성
카프카는
- 데이터 파이프라인 확장의 어려움
- 이기종 간 호환성
- 고성능 기반의 실시간 데이터 처리의 어려움
의 문제 해결을 위해 개발됨
1.1 잘란도와 트위터의 카프카 도입 사례
1.1.1 유럽 최대 온라인 패션몰 잘란도의 도전 사례
-
잘란도는 2020년 active user 가 3,100만 명을 넘어섬.
-
잘란도가 카프카를 도입하기 전
- 데이터에 대한 온갖 요구사항
- 근본적인 해결책을 모색
- event-driven system 도입 (데이터의 변화가 스트림으로 컨슈머 측에 전달되는 구조)
- 데이터를 소비하는 컨슈머들이 자신의 요구사항에 맞춰 알아서 데이터를 처리/구독
- 초기에는 이를 REST API 형태로 구현하고, 인바운드 데이터 변경 시 아웃바운드 이벤트 발송
- 그러나 동기화 방식에서 문제가 발생
- 여러 네트워크를 이용하는 환경에서 모든 변경이벤트의 올바른 전달이 보장되지 않음
- 데이터 동시성 문제, 변경이벤트를 정확한 순서로 아웃바운드에 전송하기 어려움
- 다양한 클라이언트 요구사항 존재
- 빠른 전송/배치 전송이 필요한 클라이언트는 지원 어려움
-
잘란도가 느낀 카프카 장점
- 높은 처리량: Http 기반으로 전달되는 이벤트지만 이벤트가 카프카로 처리되는 응답시간은 불과 한자릿수 밀리초 단위.
- 순서 보장: 이벤트 처리순서가 보장 (유효성 검사, 동시 수정 고려 필요 X)
- At least once 전송 방식
- 멱등성 보장, 프로듀서 재전송 시에도 데이터 변화 X
- 누락 없는 재전송 가능: 메시지 손실 X
- 한 메시지 중복 처리 가능: 복잡한 트랜잭션 필요 X
- 클라이언트가 Pull 방식으로 동작: 카프카 클라이언트가 자신의 속도로 데이터를 처리할 수 있다.
- 파티셔닝 기능: 효과적인 수평확장 가능
- 그 외 여러 기능: 로그 컴팩션 기능 (스냅샷 역할), 프로듀서-컨슈머 비동기 방식 (애플리케이션 병목 현상 파악), 모니터링 (지연문제 빠른 해결)
1.1.2 SNS 절대강자 트위터의 카프카 활용 사계
트위터는 이슈를 빠르게 노출, 관련 광고 제공, 다양한 실시간 사용 사례를 다뤄야함.
약 10년 전 맨 처음 트위터가 카프카 0.7 버전을 쓸 때는 많은 문제점이 있었다. 그래서 카프카를 포기하고 인하우스 메시지 시스템인 Event Bus 를 구축.
하지만 비용 등 다양한 문제로 다시 카프카로 전환을 고려하게 되었는데..
- 성능테스트: 당시 Event bus의 워크로드 & 일부 장애 시나리오 를 활용해 카프카 성능테스트를 진행.
- 메시지가 처리되는 양과 관계 없이
카프카 응답속도 > 이벤트 버스 응답속도임을 발견. - 성능 차이의 원인 2가지
- Event bus 는 서빙 레이어와 스토리지 레이어가 분리돼있어 hop이 하나 더 필요. 반면 카프카는 하나의 프로세스에서 함께 처리.
- Event bus 는
fsync()시 블로킹. 반면 카프카는 OS에 의존해 백그라운드로fsync()처리, 제로카피 사용
- 메시지가 처리되는 양과 관계 없이
- 강력한 커뮤니티: 카프카는 당시 이미 많은 기업에서 채택된 기술, 더 나은 개발 경험 & 더 쉬운 데이터 엔지니어링 고용
정리: 카프카를 도입하기 전 고민해봐야할 것
- 동기/비동기 데이터 전송에 대한 고민이 있는가?
- 실시간 데이터 처리에 대한 고민이 있는가?
- 현재의 데이터 처리에 한계를 느끼는가?
- 새로운 데이터 파이프라인이 복잡하다고 느끼는가?
- 데이터 처리의 비용 절감을 고려하고 있는가?
그렇다면 카프카 도입으로 상당히 많은 문제를 해결할 수 있다.
1.3 카프카의 주요 특징
높은 throughput, 낮은 latency
- 카프카를 선택하는 가장 큰 이유.
- Kafka, Pulsar, RabbitMQ 의 Throughput과 Latency를 비교한 글: https://www.confluent.io/blog/kafka-fastest-messaging-system/
- 이를 어떻게 구현해냈는지는 뒷 부분에서 자세히
높은 확장성
- 처리량이 아무리 높다해도 그 한계는 존재하므로 확장이 가능해야한다. -> 카프카는 처음부터 확장이 쉽게 설계된 애플리케이션.
- 8장에서 Kafka의 높은 확장성에 대해 더 자세히 다룸
고가용성
- 처음에는 빠른 처리 중심의 개발에서, 시간이 지나며 고가용성도 중요해짐 -> 2013년 클러스터 내 replication 기능 추가
- 고가용성을 갖추면서, 지연 없는 빠른 처리를 유지하는 것은 어려운 것임. (카프카 개발자들이 성능을 지키면서 고가용성을 어떻게 확보했는지 알 수 있는 부분!)
- 이는 4장에서 집중적으로 다룸
내구성
In software engineering, durability refers to the persistence and reliability of data and the software system itself over time, even in the face of failures or unexpected events
- 전통적인 메시징 시스템과 달리, 카프카는 컨슈머가 메시지를 가져가더라도 메시지는 삭제되지 않고 지정된 설정 시간 또는 로그의 크기만큼 로컬 디스크에 보관됨.
- 메시지들은 2-3대의 브로커의 로컬 디스크에 저장되므로 브로커 중 하나가 종료되더라도 복구가 가능하다.
- 4장에서 자세히 설명
개발 편의성
- 프로듀서와 컨슈머의 분리 (5장, 6장)
- 프로듀싱을 원하는 개발자는 프로듀서만 개발하면되고, 반대로 컨슈밍을 원하는 개발자는 컨슈머만 개발하면 된다.
- Schema Registry(8장): 카프카의 메시지 스키마를 정의해서 사용할 수 있도록 개발된 애플리케이션.
- Kafka Connect: Elasticsearch, HDFS 등 다양한 소스와의 동기화를 제공
운영/관리 편의성
- 쉬운 증설 작업
- 무중단 버전 업그레이드
- 단순한 버전 업그레이드
1.4 카프카의 성장
2011년 오픈소스 출시 이후 주요 업데이트 정리
-
리플리케이션 기능 추가(v0.8)
- 2013년 12월 리블리케이션 기능 추가.
- 내부 카프카 클러스터에서 브로커의 장애가 발생해도 데이터 유실 없이 운영 가능해짐
-
스키마 레지스트리 공개 (v0.8.2)
- 프로듀서와 컨슈머 간에 서로 데이터 구조를 설명할 수 있는 스키마를 등록 지정해 사용하는 애플리케이션.
- 초기에는 pub/sub 모델로 많은 문제를 해결했으나 규모가 커지면서 한계를 만남. 카프카를 사용하는 데이터과학자나 데이터분석가 같은 고급인력이 비정형 데이터를 파싱하는 데 많은 시간을 소모하고 있었음..
-
카프카 커넥트 공개 (v0.9)
- 기업들은 카프카를 활용해 데이터 허브를 구축하는 경우가 많아짐 (카프카와 연결되는 시스템들이 다양해짐)
- 다양한 프로토콜: DB(MySQL, PostgreSQL, MongoDB, ...), FTP, HDFS, Amazon S3, ActiveMQ, ...
- 카프카 커넥트는 별도 코드 작성 없이 다양한 프로토콜과 카프카를 연동할 수 있게 한다.
- 기업들은 카프카를 활용해 데이터 허브를 구축하는 경우가 많아짐 (카프카와 연결되는 시스템들이 다양해짐)
-
카프카 스트림즈 공개(v.0.10)
- 실시간 처리에 대한 니즈를 충족하고자 공개한 기술
- 카프카 스트림즈 클라이언트를 이용해서 실시간 처리가 가능해짐.
-
KSQL 공개
- 별도의 코드를 작성하지 않고도 SQL 기반으로 실시간 처리가 가능한 언어 개발
- 스트림 처리, 배치 처리 가능
-
주키퍼 의존성에서 해방(v3.0)
- 주키퍼: 분산 코디네이터 시스템; 카프카의 토픽, 브로커 등을 관리하는 목적으로 사용
- 주키퍼는 그간 카프카가 높은 성능을 갖는 데 장벽이 되었음.
- Confluent Cloud Is Now 100% KRaft and You Should Be Too
1.5 다양한 카프카의 사용 사례
이제 기업들은 단순히 카프카를 pub/sub 모델로만 활용하는 데 그치지 않고
- 데이터 통합
- 메시지 버스
- 실시간 데이터 처리/분석
등 여러 용도로 관련 기술들을 활용한다.
실제 사례들을 보자
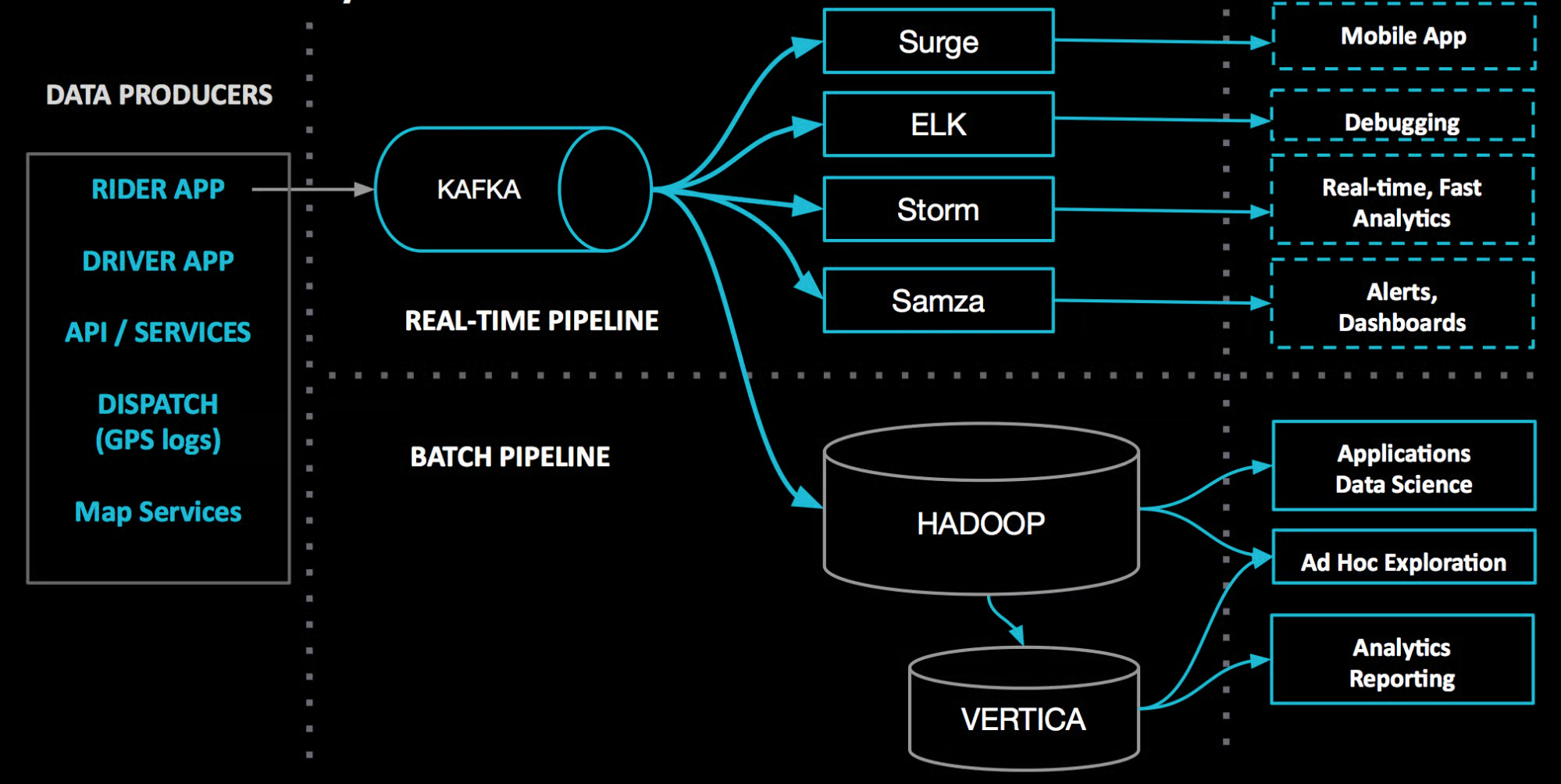
데이터 파이프라인: Netflix
- 데이터 기반 의사결정: 넷플릭스는 전 세계에서 큰 규모로 데이터를 수집, 통계, 처리, 적재하기 위한 파이프라인을 구성함.
- 이 파이프라인을 연결해주는 역할로 카프카를 사용한다.
출처: 'Evolution of the Netflix Data Pipeline' - Netflix TechBlog
사용자의 넷플릭스 비디오 시청 활동, 유저 인터페이스 사용 빈도, 에러 로그 등의 모든 이벤트가 데이터 파이프라인을 통해 흐름
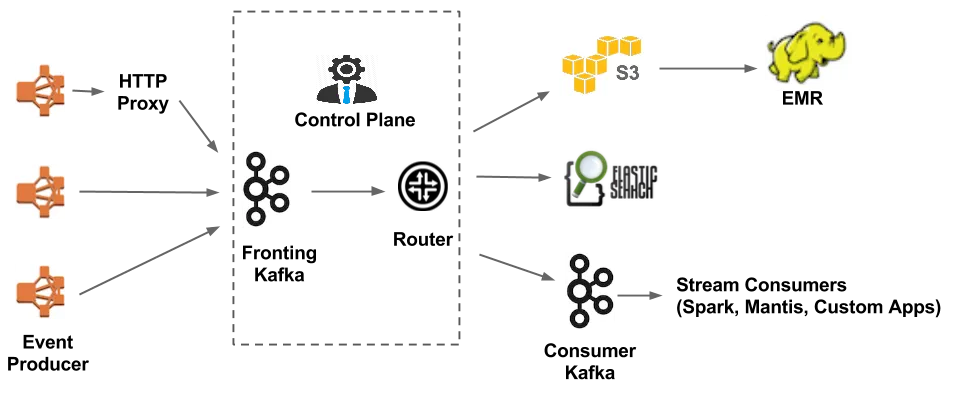
데이터 통합: Uber
- 카프카 도입 이후부터는 안정적으로 손쉽게 데이터 파이프라인의 추가가 가능해짐
출처: 'uReplicator: Uber Engineering’s Robust Apache Kafka Replicator' - Uber Blog
- 다양한 에코시스템과 메시지 버스로 카프카가 연결되어 사용되는 우버의 사례.
머신러닝 분야 활용 사례
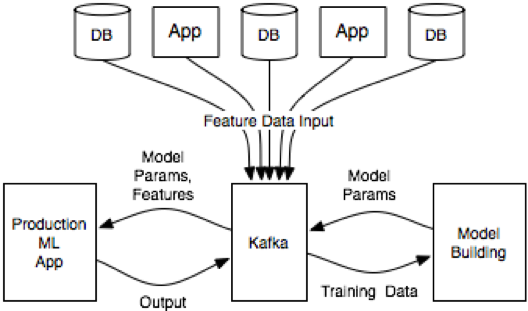
출처: 'How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka' - Confluent
1.6 정리
1장에서는
- 카프카는 오늘날 실시간 데이터 플랫폼 또는 이벤트 스트리밍 플랫폼으로 불림
- 잘란도와 트위터에서 카프카를 도입하게 된 상황
- 카프카의 주요 특성/성장 과정
- 카프카 사용 사례, 현황
을 봤고
2장에서는 실습 환경 구성을 한다.