
DBMS의 트랜잭션
2023년 8월 12일 작성
왜 DBMS를 학습해야 하나?
- 데이터 중심적인 개발을 하게 될 가능성이 높기 때문이다. 그런 관점에서는 DB를 잘 사용하는 것이 중요하다.
- 애플리케이션은 인프라에 의존하지 않아야한다는 원칙이 있지만, 그것들을 아예 고려하지 않고 애플리케이션 구현을 ‘잘’ 할 수 있을까? ⇒ 없다.
트랜잭션
트랜잭션이란?
- 논리적 작업 단위 (한 마디로)
검색시 공통적으로 나오는 키워드
- atomic units of work
- a logical unit of work
- a single unit of logic or work
트랜잭션을 안전하게 수행되기 위한 속성: ACID
- 원자성
- 일관성
- 격리성
- 지속성
InnoDB 엔진의 원자성
이렇게 하면 어떻게 될까?

두번째 실행한 인서트문은 3, tommy의 중복으로 실패한다. 그렇다면 1, neo와 2, brie는 들어갔을까? 안들어갔을까?
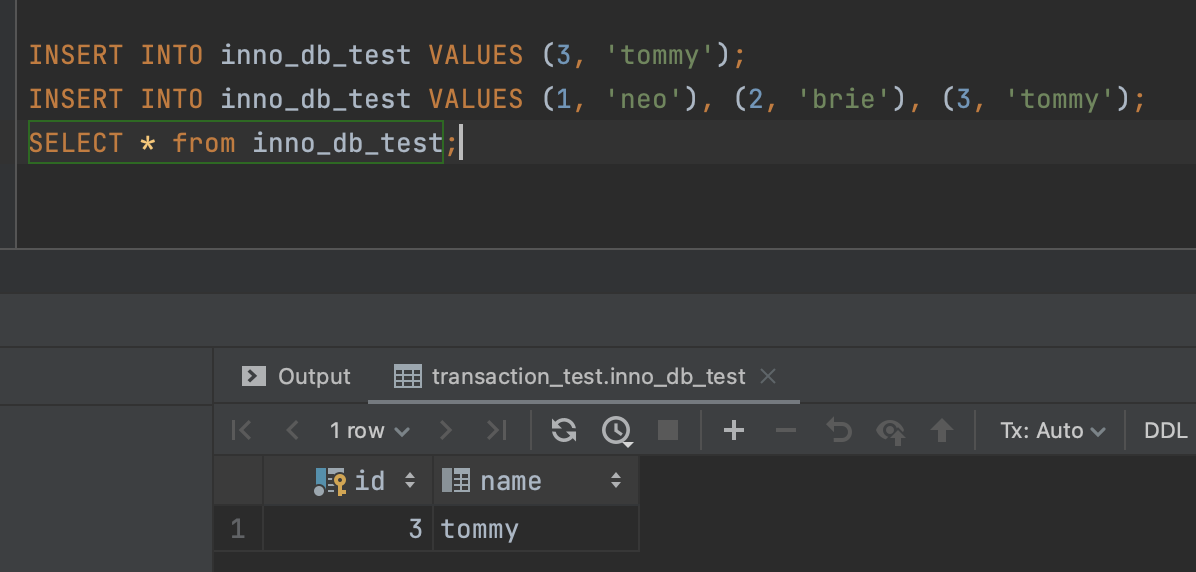
네오와 브리도 들어가지 못했다.
MyISAM 엔진의 원자성
⇒ 트랜잭션을 지원하지 않아서 결과가 다르게 나온다는데,
키가 중복되어 오류가 나는 것까지는 InnoDB 엔진과 동일하다.

그러나 테이블을 조회해보면,
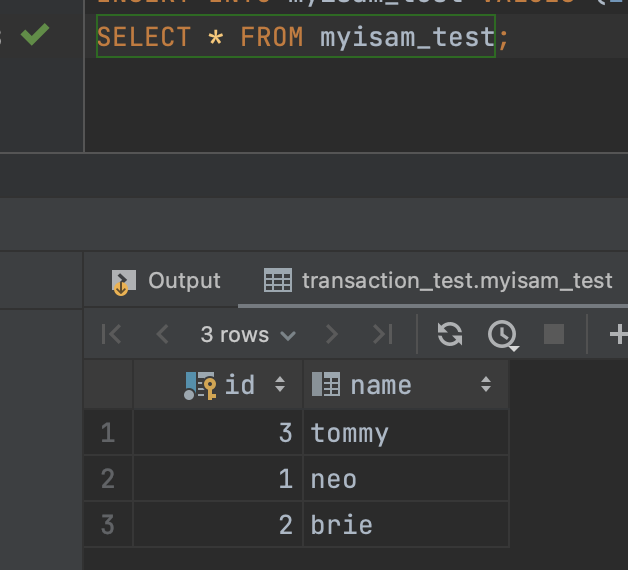
다음과 같이 결과가 나온다. (왜 순서가 3, 1, 2로 나오는지는 인덱스 이야기에서 답변.)
- 그럼 MyISAM에서는 이렇게, 오류나는 지점이 앞에있어도 뒤에는 오류가 없다면 반영이 될까?

아뇨, 안됩니다~
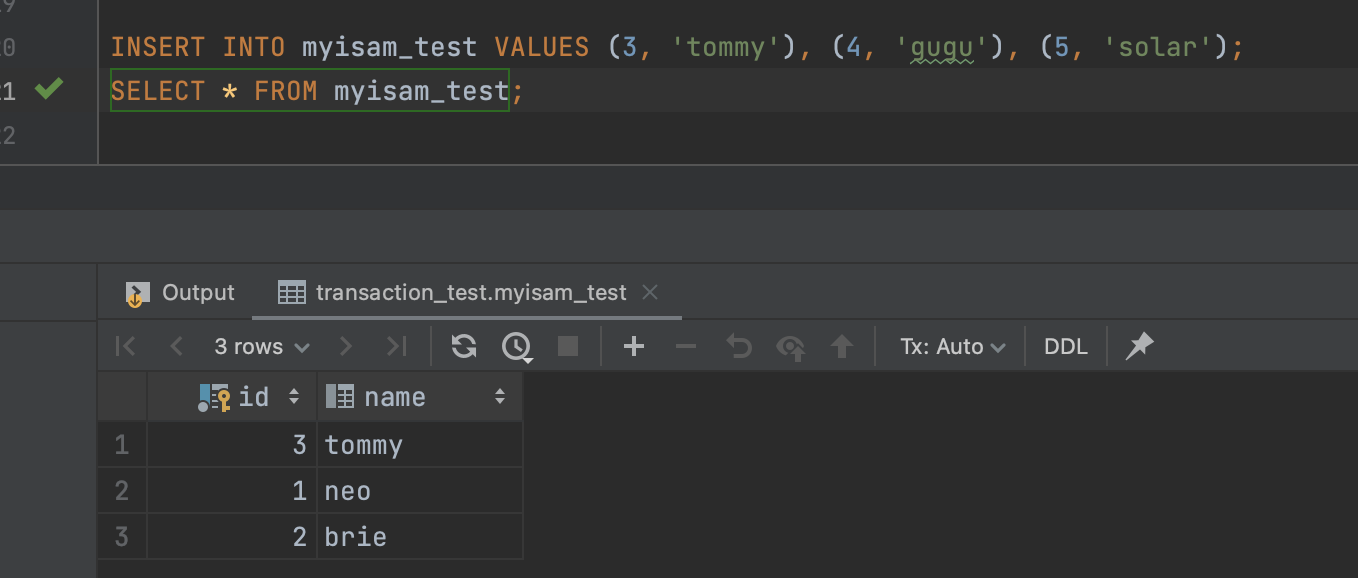
오류가 나도 롤백이 되지 않는 것일 뿐이지, 오류를 만난 이후에도 statement를 마저 실행한다는 뜻이 아니다.
InnoDB 기본 트랜잭션 동작
우리는 트랜잭션을 설정하지 않았는데, 왜 롤백이 동작했을까?
그건 바로, InnoDB가 기본적으로 트랜잭션을 사용하기 때문이다.
확인은 다음 sql을 실행해보면 알 수 있다.
select @autocommit;@autocommit이 true(1)로 되어있다면, 우리가 명시적으로 트랜잭션을 제시 하지 않아도, statement 단위로 트랜잭션이 설정된다.
격리 수준 (Isolation level)
면접에서 잘 물어보는 내용 중 하나. 이 질문에 대해 공부한다면 다양한 문제를 해결할 수 있음.
관련한 문제.
- restassured/mvc 테스트를 하는 경우 transactional의 롤백이 적용되지 않는 이유
- isolation level을 서버쪽에서는 데이터를 저장했지만, commit이 되지 않아 데이터가 저장되지 않은 것처럼 보일 수 있다.
Spring의 Transactional
- propagation은 spring에서 제공하는 기능이다.
격리수준이란?
- 트랜잭션 간에 격리되어있는 정도
- 한 트랜잭션에서 다른 트랜잭션의 데이터를 어디까지 읽을 수 있는지
- 우리는 이것을 설정해줄 수 있다.
격리 수준을 잘 알아야하는 이유
트랜잭션들이 동시에 데이터를 변경 또는 조회할 때의
- 성능
- 안정성
- 일관성
- 결과 재현성
에 대한 균형을 미세하게 조정할 수 있다.
따라서 격리수준에 따른 동작을 잘 인지하지 못하면 예상치 못한 데이터를 만나게 될 수도 있다.
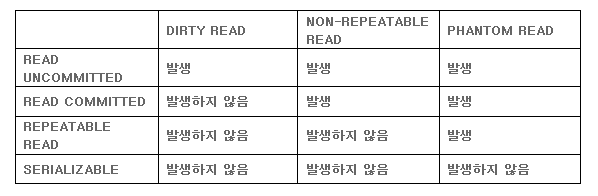
4단계 격리 수준
- InnoDB 기본 격리수준은 REPEATABLE READ 이다.
Read Uncommited
Dirty read - 커밋되지 않은 데이터를 읽을 수 있다.
| Connection A | Connection B |
|---|---|
| SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; | |
| START TRANSACTION; | |
| INSERT INTO inno_db_test VALUES (11, ‘test’); | |
| SELECT * FROM inno_db_test; // 조회 가능. Dirty read 발생 |
- 격리 수준을 read uncommited로 설정해주고
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;- 트랜잭션 시작 후, 커밋 하지 않고 insert를 한다.
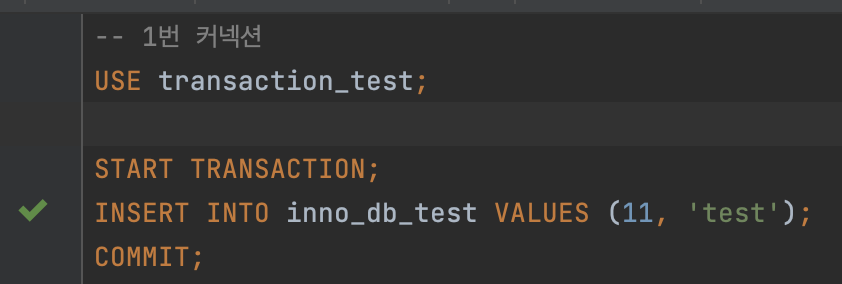
커밋하지 않은 상태로 select를 하면 어떻게 될까?
- 격리 수준의 이름 그대로, 조회가 가능하다.
⇒ Dirty read 발생
- 롤백을 한다면?
당연히 보이지 않는다.
Read Committed
서로 다른 커넥션 1번 2번이 있다고 하자. 1번에서 데이터를 삽입할 것이고 2번에서는 조회를 할 것이다.
삽입 후 커밋 없이 조회 - 실패
- 먼저 2번에서 조회를 위한 트랜잭션을 시작하기 전에, 커넥션의 격리수준을 read committed로 변경한다.
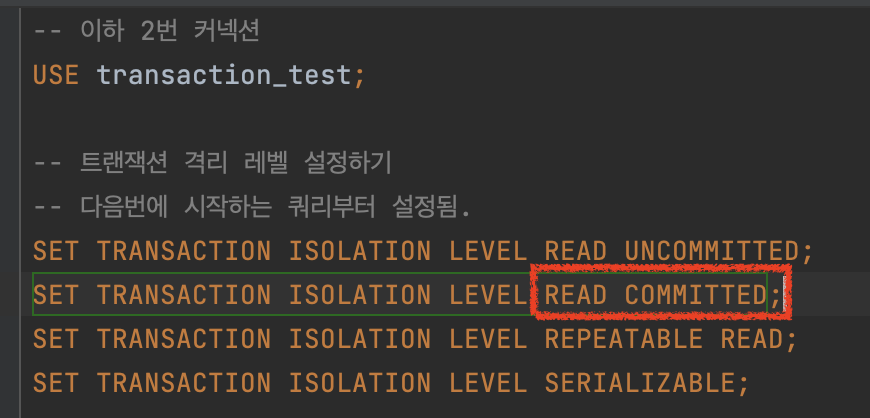
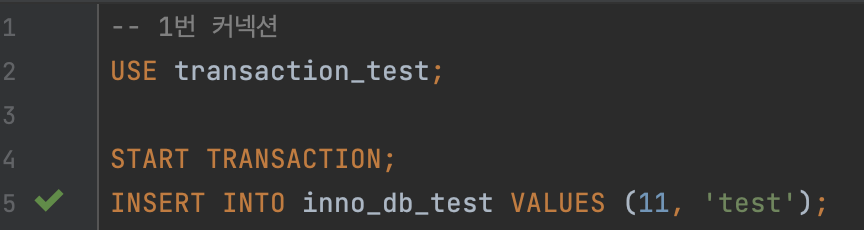
- 그리고나서 1번에서 트랜잭션을 시작하고, 데이터를 삽입한다.
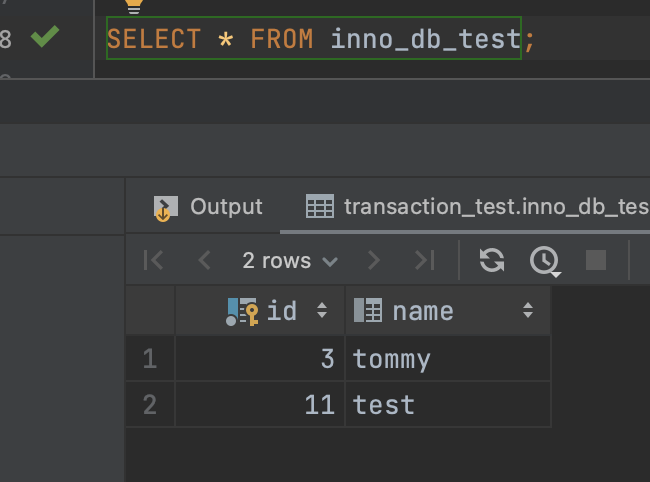
- 2번 커넥션에서 데이터를 조회한다.
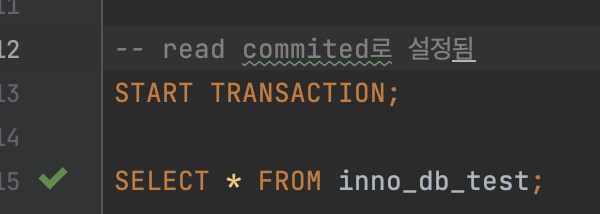
그러면 1번에서 삽입했던 데이터는 읽히지 않는다. (커밋되지 않았기 때문에)
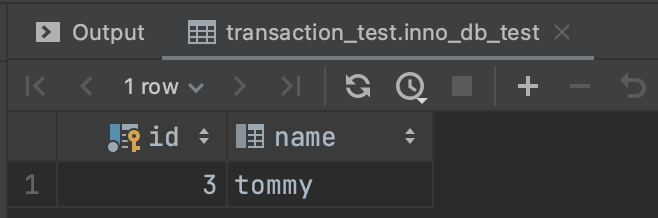
데이터 삽입 후 커밋 후 조회
- 그럼, 1번에서 커밋을 한다면?
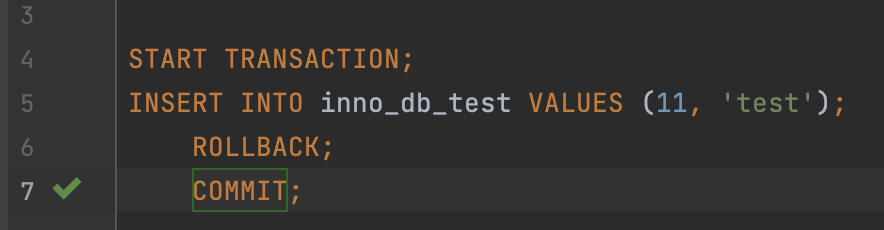
1번 커넥션: 삽입 후 커밋!
2번 커넥션에서도 (11, test)를 조회할 수 있다.
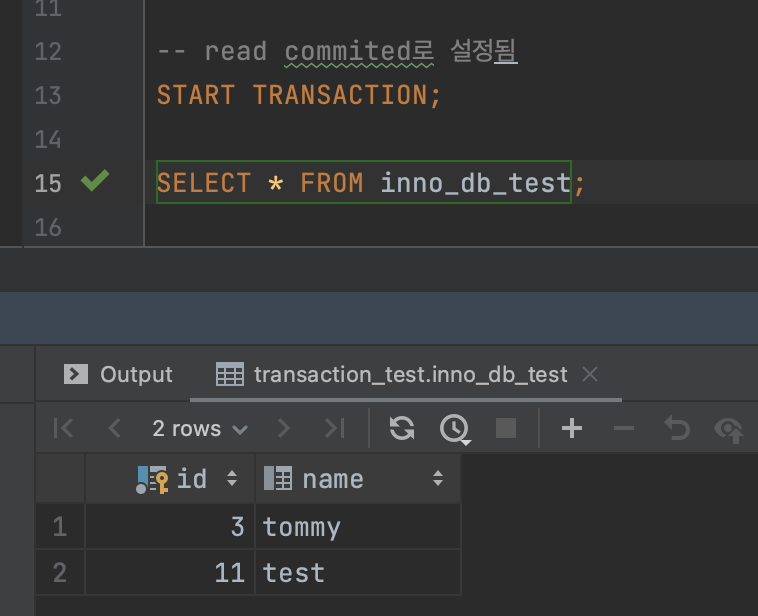
2번 커넥션(read committed) 도 조회할 수 있다!
read committed의 문제
그렇다고 하면, read committed 수준의 커넥션에서는 데이터를 읽을 때
다른 트랜잭션의 영향을 받아 읽을 때마다 데이터가 바뀔 수 있다. (non-repeatable read 발생)
Repeatable Read
다른 트랜잭션에 의한 변경(update, delete)사항이 있어도, 영향받지 않음
| Connection A | Connection B |
|---|---|
| INSERT INTO inno_db_test VALUES (12, ‘test’); | |
| SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; | |
| START TRANSACTION; | |
| SELECT * FROM inno_db_test; // 12, test 로 조회됨 😃 | |
| START TRANSACTION; | |
| UPDATE inno_db_test SET name = ‘update’ WHERE id = 12; | |
| COMMIT; | |
| SELECT * FROM inno_db_test; // 여전히 12, test 로 조회됨 😃 | |
| COMMIT; |
MySQL의 경우, (MVCC 덕분에) 다른 트랜잭션에서 삽입 연산이 있어도 단순조회하는 경우 영향받지 않음
| Connection A | Connection B |
|---|---|
| SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; | |
| START TRANSACTION; | |
| START TRANSACTION; | |
| INSERT INTO inno_db_test VALUES (12, ‘test’); | |
| SELECT * FROM inno_db_test; // 12번 레코드 조회되지 않음 😃 |
- 이제 2번의 격리 수준을 다음으로 변경해보자.
- 2번 커넥션의 격리수준을 Repeatable read로 변경하기. 그 후 조회 트랜잭션을 시작!!
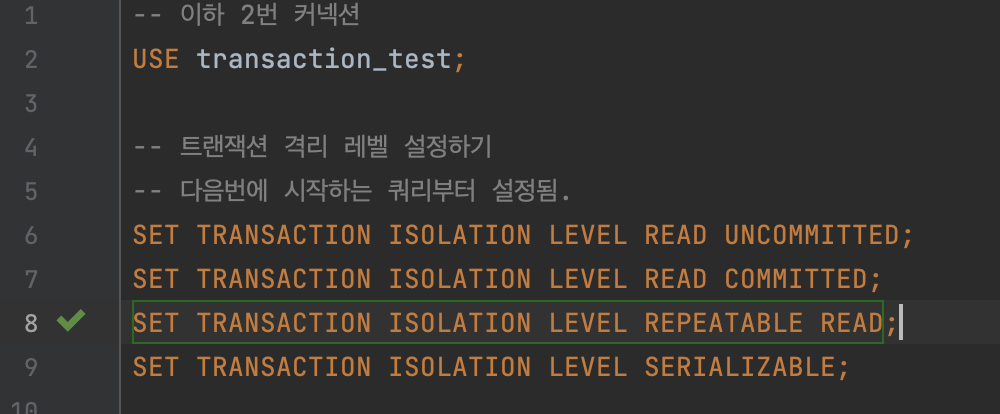

2번 커넥션 트랜잭션 시작.
- 1번 커넥션에서 트랜잭션 시작 후 데이터 (12, ‘test’) 삽입, 커밋까지한다.
- 2번에서 조회했을 때도 끄떡없다. 왜냐면 2번 커넥션의 격리 수준은 repeatable read, 즉 반복해서 조회할 때 값이 보장되기 때문이다. 기본적으로 다른 트랜잭션에서 변경한 작업 내역이 보이지 않는다.
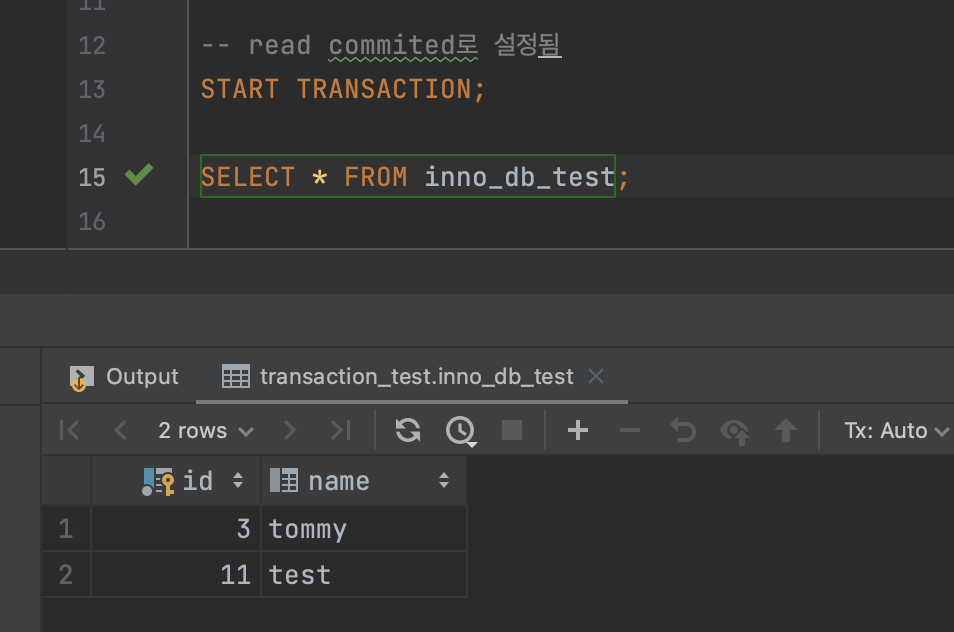
2번(repeatable read) 트랜잭션은 꿋꿋하게 영향받지 않는군! (흐뭇)
오, 그러면 repeatable read는 (이론상) 한 번 읽은 값은 계속 같은 값으로 읽히겠구나~
Phantom read
그러나 문제가 있다.
- 방금같이 1번 커넥션에서 데이터 insertion을 커밋하고도 영향 받지 않았었는데.. (위에 참조) 2번에서 그 새로운 데이터를 update 하는 스크립트를 실행하고 나면

(1번 커넥션에서 삽입했던) 12번을 update한 뒤 다시 조회
- 조회가 되는 Phantom read 현상이 발생한다. (엥! 네가 왜 여기있니?)
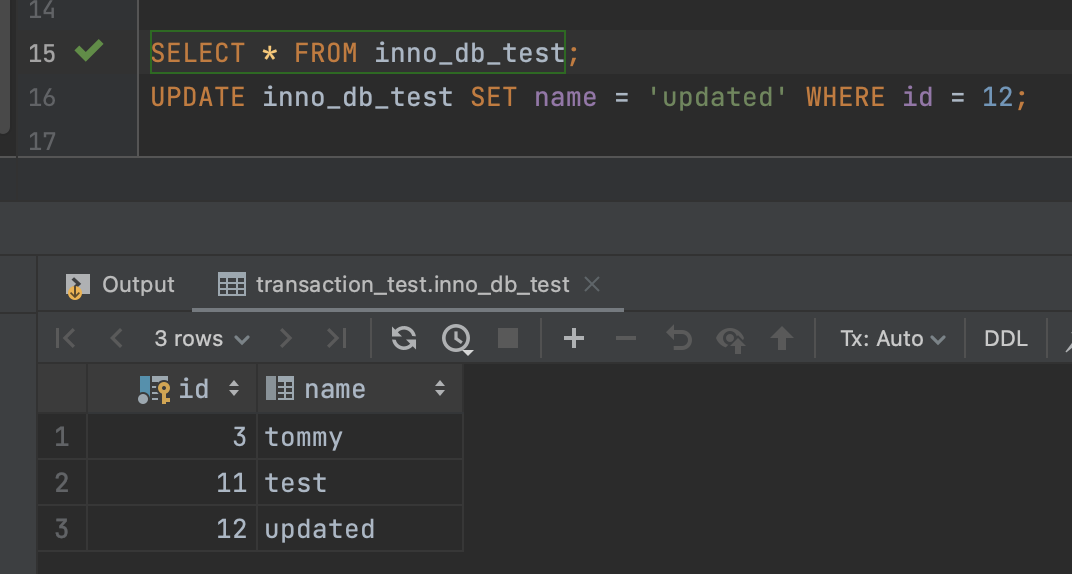
다시 조회가 된다.
이게 바로 phantom read이다. (내 트랜잭션 시작하기 전에는 없었는데, 다른 트랜잭션에서 커밋된 변경사항이 읽히는 현상) 안 읽혔으면 끝까지 안읽혀야하는게 repeatable read인데…
아까 처음 조회했을 때 phantom read가 일어나지 않은 것도, Mysql만 잘 지켜지는 거라고 한다. (by. mvcc) 원래 다른 데이터베이스는 repeatable read여도, 원래 없었던 새로운 데이터가 삽입되는 경우 영향을 받아 phantom read가 일어난다고 한다.
- mvcc 덕분에, 다른 테이블에 있는 값도 특정 시점의 데이터를 읽어올 수 있다.
Serializable
serializable은 트랜잭션 각각이 완전히 독립적일 수 있는 격리 수준이다. serializable 이라는 말 자체가 나눌 수 있다는 말이니..
serialize something to publish or broadcast something in parts as a serial
즉, 트랜잭션을 독립적으로 직렬화할 수 있는 수준을 뜻한다. 트랜잭션이 커밋/롤백되는 시점을 기준으로 순서를 매길 수 있다. ex) 트랜잭션 A, B가 있다고 하자. A가 먼저 시작되어도 B가 먼저 커밋/롤백 되면 B의 순서가 앞이라고 본다.
Serializable 사용시 다른 트랜잭션에서 변경이 불가능
공유 잠금 (Shared Lock)
레코드에 락을 걸고, 다른 트랜잭션에서 변경하지 못하도록 한다.
| conncection A | conncection B |
|---|---|
| SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; | |
| START TRANSACTION; | |
| SELECT * FROM inno_db_test; → 락 실행 | |
| START TRANSACTION; | |
| INSERT INTO inno_db_test VALUES (11, 'test'); → wait 1 | |
| UPDATE inno_db_test SET name = 'updated' WHERE id = 12; → wait 2 | |
| COMMIT; → 락 해제 | |
| wait 1과 wait2 반영 됨. |

B트랜잭션에서 테이블에 락을 걸어둔 상태. B 트랜잭션이 종료되기를 기다려야한다.

update도 마찬가지.
Serializable 좋네! 그냥 이거 쓰면 되는거 아냐?
NO. repeatable read가 적절한 상황이 있다.
ex) order, order_item 테이블이 있다고 하자. repeatable read를 사용한다면, 주문 정보를 조회하는 트랜잭션에서, order와 order_item을 어떤 경우에서도 함께 조회할 수 있게 된다.
반면에 serializable을 사용하게 되면, 주문정보를 조회하는 트랜잭션에서 order를 읽은 뒤 같은 시점의 order_item 데이터를 읽고 싶은데 다른 트랜잭션이 order_item을 변경한다면(shared lock) 그것이 불가능해진다. 그렇게 되면 order(주문정보)와 order_item(주문상품) 데이터 간 불일치가 일어날 수 있다.